When teams operate independently, it creates communication gaps that can lead to disorder. In contrast, when teams collaborate, they tend to be more efficient.
In the fast-paced world of software development and operations, two terms have gained significant attention in recent years: DevOps and MLOps. Both are methodologies aimed at streamlining and enhancing the software development process, but they have distinct focuses and applications. In this article, we will delve into the differences between DevOps and MLOps, shedding light on their unique characteristics and how they serve their respective domains.
Machine learning is a term almost everyone in the IT space has heard by now—but it’s not just a buzzword used in flashy presentations anymore. As machine learning has started to become more applied and less theoretical, the industry has begun to incorporate it into important projects.
When comparing MLOps vs DevOps, it’s essential to recognize the specialized practices required for managing machine learning models alongside traditional software development.
A collection of procedures known as DevOps attempts to speed up the development life cycle of a system and offer continuous delivery of high-quality software. In contrast, MLOps refers to the process of automating and productionalizing machine learning workflows and applications. Both DevOps and MLOps strive to integrate a piece of software into a dependable and repeatable workflow, but MLOps also includes a machine learning component. DevOps automation is essential for reducing manual errors and ensuring seamless integration.
Transitioning from DevOps to MLOps requires adapting your development and deployment practices to accommodate the unique challenges of managing machine learning models effectively.
DevOps principles emphasize the following key aspects:
DevOps encourages the automation of repetitive tasks, such as code integration, testing, deployment, and infrastructure provisioning. This automation reduces manual errors and accelerates the development process.
CI involves regularly integrating code changes into a shared repository. Automated testing is performed on these changes to identify and address issues early in the development cycle.
CD extends CI by automatically deploying code changes to production or staging environments once they pass all tests. This ensures that software updates can be delivered quickly and reliably.
DevOps fosters collaboration and communication between development and operations teams, breaking down silos and promoting a shared responsibility for the entire software delivery lifecycle.
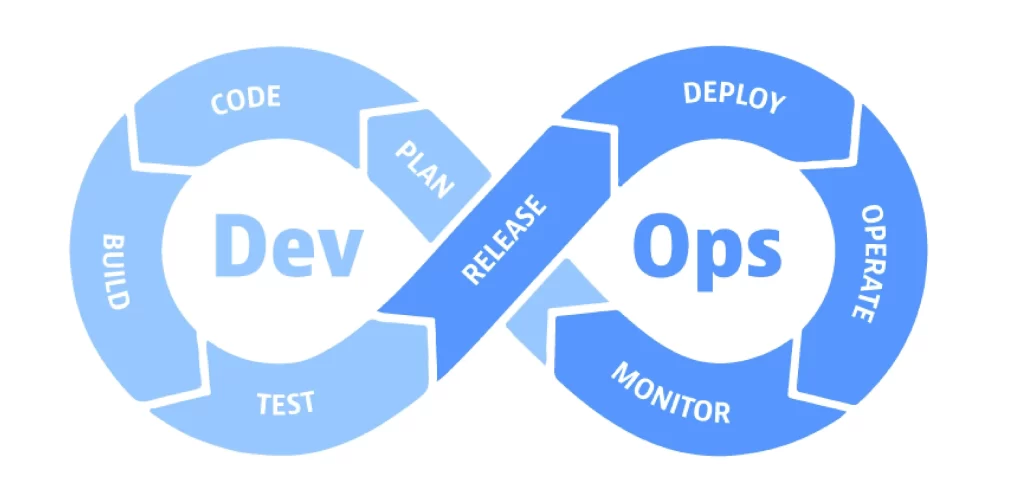
As teams strive for a quicker code-build-deploy cycle, DevOps is a key idea in almost all successful IT projects. This gives teams the ability to deploy new features more quickly, allowing them to complete projects more quickly and with higher-quality results. However, without the right DevOps procedures, teams struggle with manual work, testing limitations, and eventually dangerous production deployments.
For a successful DevOps project, an ideal DevOps cycle will be comprised of the following five key pillars:
MLOps, short for Machine Learning Operations, is an emerging discipline that focuses on the unique challenges of deploying and managing machine learning models in production environments. While DevOps principles can be applied to traditional software development, MLOps is tailored to the needs of machine learning projects. Here are some key characteristics of MLOps:
In MLOps, the entire machine learning model’s life cycle is managed, including data collection, preprocessing, model training, testing, deployment, monitoring, and retraining. This holistic approach ensures that models remain accurate and effective over time.
High-quality data is crucial for machine learning models. MLOps emphasizes data versioning, lineage tracking, and data quality monitoring to ensure that models receive reliable inputs.
Just as code undergoes version control in DevOps, MLOps applies version control to machine learning models. This allows for easy tracking of model changes and rollbacks when necessary.
MLOps provides tools and practices for deploying machine learning models into production environments, where they can make real-time predictions or recommendations. It addresses challenges related to model scaling, latency, and compatibility with various deployment targets.
MLOps incorporates continuous monitoring of deployed models to detect drift (changes in data distribution), performance degradation, or accuracy issues. When such issues are identified, the system can trigger retraining processes automatically.
MLOps, short for Machine Learning Operations, is a set of practices and stages that aim to streamline and automate the deployment, monitoring, and management of machine learning models.
Here are the key stages in the MLOps process:
In the initial stage of MLOps, it’s crucial to define the problem you want your machine learning model to solve. This involves understanding the business context and objectives. Once the problem is defined, the next step is to collect and preprocess the data required for model training and evaluation. High-quality data is the foundation of any successful machine-learning project, and this stage sets the groundwork for subsequent phases.
Data preprocessing is where you clean and prepare the collected data. This involves handling missing values, outliers, and other data anomalies that can affect model performance. Additionally, feature engineering is performed to create relevant and informative input features for the machine learning model. Proper data preprocessing ensures that the model can learn meaningful patterns from the data.
In this stage, you select an appropriate machine learning algorithm or model architecture based on the problem and data characteristics. You then train the model using the prepared data. Model development also includes hyperparameter tuning to optimize the model’s performance. This phase is where the core of your machine-learning solution is built.
Model evaluation is critical to assess how well your trained model performs. You use relevant evaluation metrics to measure the model’s accuracy, precision, recall, or other performance indicators, depending on the problem domain. Validation against a separate dataset helps identify potential overfitting issues. A well-evaluated model provides confidence in its ability to make accurate predictions.
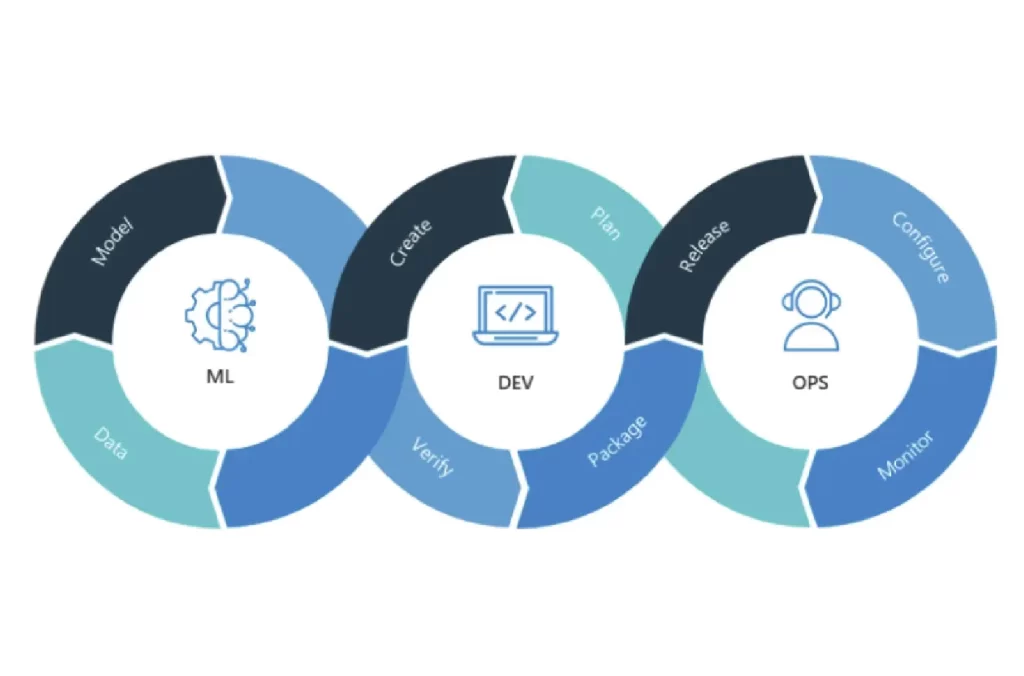
The code-validate-deploy cycle is a component of both DevOps and MLOps pipelines. To develop or train a machine learning model, however, the MLOps pipeline also includes extra data and model phases (see diagram below). This indicates that MLOps eventually has a few subtle differences from traditional DevOps for each component of the workflow.
Despite being ambiguous terms, “data” and “model” typically refer to the processes of data labeling, data transformation/feature engineering, and algorithm selection.
The majority of industry machine learning projects use supervised algorithms nowadays. This indicates that during the model training process, they have a goal (or label) to learn from. The process of data labeling is adding the target to a group of records in order to create a training set for the model.
Data transformation and feature engineering are necessary because models require particular types of data in order to deliver useful results. The kind of prediction problem at hand must be taken into account while choosing an algorithm.
Overall, this adheres to the CRISP-DM process model, which has emerged as the standard operating procedure for data science initiatives as of 2022.
At a high level, the “Dev” and “Ops” components are largely the same. In the parts that follow, we’ll talk about low-level distinctions.
In each concept, “development” has two distinct meanings.
You’ll likely have code that generates some form of application or interface on the traditional DevOps side. The code is subsequently contained in an executable (artifact), which is then released and put to use before being checked against a set of tests. The ideal version of this cycle is automated, and it goes on until you get the finished item.
MLOps, on the other hand, uses code to create/train a machine learning model. Here, the output artifact is a serialized file that may accept input data and provide conclusions. The trained model’s performance versus test data would be evaluated during validation. Similar to the previous cycle, this one keeps going until the model’s performance reaches a particular level.
When conducting an MLOps platform comparison, it’s crucial to assess factors such as scalability, integration capabilities, and support for various machine learning frameworks to determine the best fit for your organization’s needs.
Tracking changes to code and artifacts is often all that version control in a DevOps pipeline entails. A MLOps pipeline has greater tracking requirements.
As previously indicated, model construction and training entail an iterative cycle of experimentation. To accurately recreate an experimental run later on for auditing purposes, its components and metrics must be tracked. The data set utilized for training (train/test split), the model construction code, and the model artifact are some examples of these components. Hyper-parameters and model performance, such as error rate, are included in the metrics.
This could seem like a lot of information to track compared to conventional software solutions. We are fortunate to have model registry tools that are a perfect fit for versioning ML models.
Roles and responsibilities differ slightly between traditional DevOps and MLOps.
In DevOps, software engineers are the ones developing the code itself while DevOps engineers are focused on deployment and creating a CI/CD pipeline. In MLOps, data scientists play the role of the application developers as they write the code to build the models. MLOps engineers (or machine learning engineers) are responsible for the deployment and monitoring of these models in production.
Code | Artifact | Validation | Roles | |
|---|---|---|---|---|
DevOps |
| Executable JAR | Unit testing |
|
MLOps |
| Serialized file | Model performance (error rate) |
|
MLOps is not a ground-breaking concept. In essence, MLOps is a particular application of DevOps; it is DevOps for machine learning pipelines and projects. If you bear in mind the particular discussed here, if you are familiar with DevOps, you should have no trouble picking up the concepts of MLOps.
In a technology-driven world, understanding the differences between these two disciplines is essential for organizations aiming to stay competitive and innovative in their respective fields. The key difference between MLOps and DevOps lies in their respective focuses and share many core principles, they cater to different domains and have specific areas of expertise. DevOps focuses on streamlining software development and deployment, while MLOps tailors these principles to the unique challenges of machine learning projects. Many organizations rely on DevOps services to streamline their software development pipelines and accelerate the delivery of high-quality applications to the market.
Follow IntellicoTalks for more insights!


Talk to us and let’s build something great together
A Subsidiary of Vaival Technologies, LLC
IntelliCoworks is a leading DevOps, SecOps and DataOps service provider and specializes in delivering tailored solutions using the latest technologies to serve various industries. Our DevOps engineers help companies with the endless process of securing both data and operations.
Ops
Cloud
AI & ML
Copyrights © 2023 byIntellicoworks. All rights reserved.