Distributed Machine Learning: Algorithms, Frameworks and its Benefits
When teams operate independently, it creates communication gaps that can lead to disorder. In contrast, when teams collaborate, they tend to be more efficient.
What is Distributed Machine Learning?
Distributed Machine Learning (DML) involves training machine learning models across multiple devices or servers, sharing the workload, and enhancing computational efficiency. Unlike traditional machine learning approaches, distributed frameworks distribute tasks, allowing for parallel processing and accelerated model training.
According to a survey by O’Reilly, 85% of respondents reported using distributed computing frameworks in their machine learning workflows, showcasing the widespread adoption of distributed approaches. Recent advances in deep learning have produced some intriguing state-of-the-art outcomes, particularly in computer vision and natural language processing. A few of the factors contributing to the success are often the abundance of data available and the growing size of deep learning (DL) models. These algorithms can determine correlations between the input and the output and extract relevant patterns. It is also true that it can take days or even weeks to design and train these intricate algorithms.
A quick and effective method to build and produce new models is required to handle this issue. These models cannot be trained on a single GPU due to the information bottleneck that would arise. Multi-core GPUs are required to address the problem of information bottlenecks on a single-core GPU. This is where the concept of dispersed training becomes relevant. The synergy between Distributed Machine Learning and DevOps services empowers organizations to seamlessly integrate intelligent algorithms, enabling agile development and deployment cycles for enhanced efficiency and innovation.
Distributed Training
Scalability, or the DL algorithm’s capacity to process or learn from any volume of data, is a prerequisite for most DL training. In essence, three elements determine whether a DL algorithm is scalable:
- Size and the complexity of the deep learning model
- Amount of training data
- Infrastructure, like storage units and GPUs, should be readily available, and these devices should integrate seamlessly with one another.
All three requirements are satisfied by distributed training. It manages the size and complexity of the model, processes training data in batches, and divides and disperses the training process among several processors known as nodes. More importantly, it drastically cuts down on training time, resulting in shorter iterations and faster experimentation and deployment.
Distributed training is of two types:
- Data-parallel training
- Model-parallel training
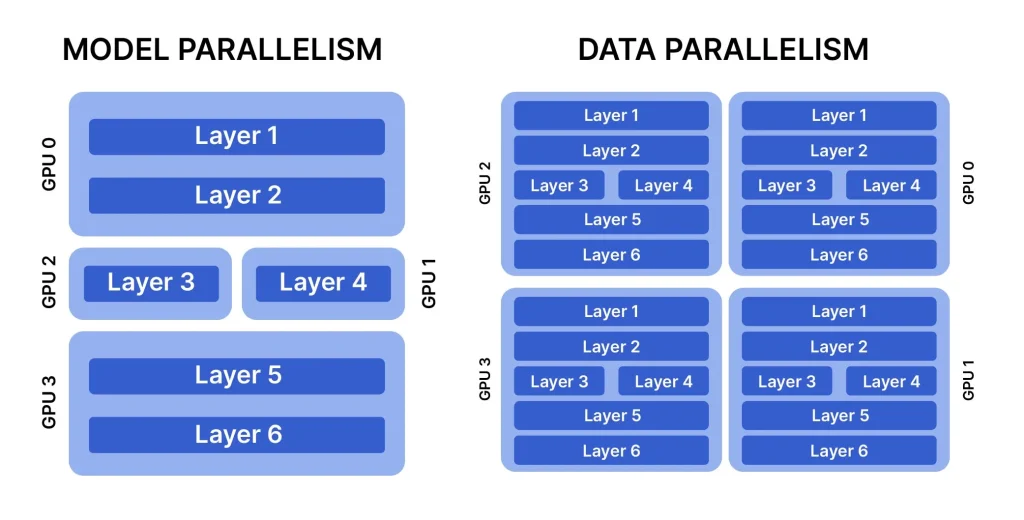
1. Data Parallel
The data is separated into subsets for data-parallel training according to the number of nodes that are accessible for training. Additionally, every available node shares the same model architecture. To make sure that the training at each node is in sync with the others, all of the nodes must interact with one another during the training process. It is the most widely used method and the most effective strategy to train the model.
Depending on how many worker nodes are in the system, the data is split up. Every employee uses the same process on different data partitions. When every worker node has access to the same model, a single coherent output is produced (either by centralization or replication). For the majority of machine learning techniques, this assumes that data samples are dispersed i.e. independently and identically.
2. Model-parallel
The DL model is divided into segments according to the number of available nodes in model-parallel training. The same data is provided to every node. The DL model is divided into many segments for model-parallel training, and each segment is subsequently input into a separate node.
A machine learning technique called model parallelism divides a neural network model across multiple processors or computing devices. Model parallelism divides the parameters of the neural network model among multiple machines so that each machine can process a portion of the input data and decide the appropriate output.
Distributed Machine Learning Algorithms
Distributed machine learning algorithms play a crucial role in training complex models on vast datasets distributed across multiple nodes or devices. These algorithms are designed to harness the power of parallel processing, enabling efficient and scalable model training. Here are some widely used machine learning algorithms:
1. Distributed Stochastic Gradient Descent
Stochastic Gradient Descent (SGD) is a popular optimization algorithm used for training machine learning models. In the distributed setting, DSGD distributes the data across multiple nodes, and each node computes gradients independently. These gradients are then averaged or combined to update the global model.
2. Parameter Server Algorithms
Parameter server architectures are commonly used in distributed machine learning frameworks. Algorithms like Hogwild! and Downpour SGD employ parameter servers to distribute model parameters across multiple nodes. Workers update parameters independently, and the server aggregates updates.
3. AllReduce and Ring-AllReduce
AllReduce is a collective communication operation used for distributing model parameters and aggregating updates in distributed deep learning. Ring-AllReduce, a variant of AllReduce, is particularly efficient for distributed training across GPUs and nodes. Horovod is an example of a framework that uses Ring-AllReduce.
4. Model Averaging
Model Averaging involves training multiple copies of a model on different subsets of the data and then averaging their parameters. This approach is especially useful for assembling models in a distributed setting. Federated Learning, a technique for training models across decentralized devices, often uses model averaging.
5. Asynchronous Stochastic Gradient Descent
ASGD is an extension of the traditional SGD algorithm designed for distributed settings. In ASGD, nodes update model parameters asynchronously, without waiting for other nodes to complete their updates. This approach can lead to faster convergence but requires careful handling to avoid conflicts.
6. Communication-efficient Distributed Optimization
CoCoA is an optimization algorithm designed for convex optimization problems in a distributed setting. It allows nodes to communicate selectively, reducing the overall communication overhead. It is particularly suitable for scenarios where communication between nodes is a bottleneck.
7. Parallel K-Means
K-Means is a clustering algorithm that assigns data points to clusters based on their similarity. In the distributed setting, parallel K-Means algorithms distribute the data across multiple nodes, with each node performing local K-Means clustering. The cluster centroids are then updated by aggregating information from all nodes.
Distributed Machine Learning Frameworks
Distributed training frameworks are essential components in the realm of machine learning and artificial intelligence, enabling the parallelization and scaling of model training across multiple nodes or devices. Here are some prominent frameworks that facilitate distributed training:

TensorFlow
TensorFlow, developed by Google, is a widely used open-source machine learning framework. TensorFlow supports distributed training through its TensorFlow Distribute Strategy API. Users can leverage strategies such as MirroredStrategy for synchronous training on multiple GPUs or TPUStrategy for training on Google’s Tensor Processing Units.
PyTorch
PyTorch, an open-source deep learning framework, provides support for distributed training through its torch. PyTorch allows users to leverage the DataParallel module for data parallelism and DistributedDataParallel for more advanced distributed training scenarios.
Horovod
Horovod is an open-source distributed deep-learning framework developed by Uber. It uses Ring-AllReduce for efficient distributed training across multiple GPUs and supports popular deep-learning frameworks such as TensorFlow, PyTorch, and Keras.
Apache Spark MLlib
Apache Spark is a fast and general-purpose cluster computing system. Spark MLlib, its machine learning library, supports distributed training for certain algorithms. It’s particularly well-suited for large-scale data processing and machine-learning tasks in a distributed environment.
MXNet
Apache MXNet is an open-source deep-learning framework designed for both flexibility and efficiency. MXNet supports distributed training through its module API, allowing users to train models across multiple devices or nodes.
Microsoft Cognitive Toolkit (CNTK)
CNTK is an open-source deep learning toolkit developed by Microsoft. It provides support for distributed training through the DataParallelSGD and BlockMomentumSGD parallelization methods.
Ray Tune
Ray Tune is part of the Ray Project and is primarily focused on hyperparameter tuning. While not a traditional machine learning framework, it provides a scalable and distributed solution for hyperparameter search, making it a valuable addition to the training pipeline.
Dask-ML
Dask-ML is an extension of Dask, a parallel computing library. Dask-ML provides machine learning algorithms compatible with sci-kit-learn. It allows users to scale out their machine-learning workflows in a cluster.
Framework | Scalability | Training Time Efficiency | Resource Utilization | Fault Tolerance | Model Accuracy Improvement |
|---|---|---|---|---|---|
| TensorFlow | High | Very High | High | Yes | Yes |
| PyTorch | Moderate to High | High | Moderate to High | Yes | Yes |
| Horovod | High | Very High | High | Yes | Yes |
| Apache Spark MLlib | Very High | Moderate to High | Very High | Yes | Moderate |
| MXNet | High | High | High | Yes | Yes |
Benefits of Distributed Machine Learning
1. Scalability
One of the primary advantages of distributed frameworks is scalability. As data volumes explode, traditional machine-learning models might struggle to cope. Distributed frameworks enable seamless scaling by distributing tasks across multiple nodes, ensuring optimal performance even with massive datasets.
2. Faster Training Times
Parallel processing, a hallmark of distributed systems, significantly reduces model training times. Tasks are divided among various processors, enabling simultaneous computation. This results in faster convergence and shorter training cycles, a critical factor in time-sensitive applications.
3. Resource Efficiency
Distributing the workload-optimized resource utilization. Instead of relying on a single powerful machine, distributed frameworks leverage the combined computing power of multiple nodes. This not only enhances efficiency but also makes better use of available resources, reducing the overall cost of computation.
4. Improved Fault Tolerance
Distributed systems are inherently fault-tolerant. If one node fails, the system can continue functioning using the remaining nodes. This robustness ensures uninterrupted machine learning processes, critical in real-time applications where downtime is not an option.
5. Enhanced Model Accuracy
The collaborative nature of distributed learning enables models to learn from diverse datasets. This diversity often leads to more robust models, as they can generalize better to new, unseen data. Distributed frameworks facilitate aggregating knowledge from various sources, contributing to improved model accuracy.
6. Versatility Across Industries
Distributed machine learning frameworks find applications across various industries, from healthcare to finance and manufacturing. Their versatility makes them adaptable to a wide range of use cases, including predictive maintenance, fraud detection, image recognition, and natural language processing.
7. Optimized for Big Data
With the rise of big data, traditional machine learning frameworks may struggle to handle the sheer volume of information. Distributed frameworks are specifically designed to tackle big data challenges, making them indispensable in an era where data is king.
Challenges for Distributed Machine Learning
DML offers significant advantages in terms of scalability and efficiency, but it also comes with its own set of challenges. Addressing these challenges is crucial for ensuring the successful implementation and deployment of machine learning systems. Here are some key challenges associated with distributed machine learning:
1. Communication Overhead
In a distributed system, nodes need to communicate with each other to share information, synchronize updates, and aggregate results. The communication overhead can become a bottleneck, especially as the number of nodes increases. Efficient communication protocols and algorithms are required to minimize this overhead.
2. Data Distribution and Imbalance
Distributing data across multiple nodes can introduce challenges related to data distribution and imbalance. Ensuring that each node receives a representative subset of the data is crucial for maintaining model accuracy. Imbalanced data distribution can lead to some nodes finishing their work faster than others, causing idle time.
3. Synchronization and Consistency
Maintaining synchronization and consistency across distributed nodes is a complex task. In algorithms like distributed stochastic gradient descent (DSGD), nodes perform updates independently and must synchronize their parameters periodically. Ensuring consistency while avoiding unnecessary synchronization delays is a delicate balance.
4. Fault Tolerance
Distributed systems are prone to node failures, network partitions, or other issues. Designing algorithms that are resilient to failures and ensuring the continuity of model training in the presence of faults is a critical aspect of distributed machine learning.
5. Scalability
While one of the primary advantages of distributed systems is scalability, achieving optimal scalability can be challenging. As the number of nodes increases, the efficiency of parallelization may decrease due to communication overhead, leading to diminishing returns.
6. Data Privacy and Security
In distributed environments where data is distributed across multiple nodes or devices, ensuring data privacy and security becomes a significant concern. Federated learning and other privacy-preserving techniques aim to address these challenges by training models without centralized data access.
7. Resource Management
Efficiently managing computational resources is crucial for achieving optimal performance in distributed machine learning. This includes balancing the computational load across nodes, managing memory efficiently, and ensuring that nodes have access to the necessary resources for training.
8. Debugging and Monitoring
Debugging and monitoring distributed machine learning systems can be challenging. Identifying and diagnosing issues related to node failures, communication errors, or algorithmic discrepancies require advanced monitoring tools and debugging techniques tailored to distributed environments.
Real-world Applications of Distributed Machine Learning
Distributed machine learning has found widespread applications across various industries, revolutionizing the way businesses leverage large datasets and complex models. Here are some real-world applications of distributed machine learning:
Manufacturing and Predictive Maintenance
In the manufacturing industry, distributed machine learning is applied to predict equipment failures and optimize maintenance schedules. Sensors distributed across production lines collect data, which is then analyzed to anticipate potential issues, reduce downtime, and optimize maintenance costs.
Energy Management
In the energy sector, distributed machine learning is used for demand forecasting, grid optimization, and predictive maintenance of infrastructure. By analyzing data from sensors and smart meters across the grid, energy companies can optimize distribution and reduce inefficiencies.
Financial Services
Financial institutions use distributed machine learning for fraud detection, risk assessment, and algorithmic trading. By analyzing vast amounts of transactional data distributed across multiple sources, these systems can identify patterns and anomalies more effectively than traditional models.
E-commerce and Recommendation Systems
E-commerce platforms utilize distributed machine learning to enhance recommendation systems. By analyzing user behavior and purchase history across a distributed network, these systems provide personalized product recommendations, improving customer engagement and increasing sales.
Conclusion
Large-scale machine learning models must be trained on enormous datasets using distributed machine learning. Organizations may improve the accuracy and scalability of their solutions while cutting training time and costs dramatically by harnessing the power of distributed computing. As technology continues to advance, the demand for AI development services has surged, with businesses seeking cutting-edge solutions to enhance efficiency and stay competitive in today’s dynamic market. In the era of rapidly evolving technologies, businesses are increasingly adopting distributed AI solutions to harness the power of decentralized processing and collaborative intelligence for more efficient and scalable machine learning applications.
Transform Data into Insights With Our AI Development Services !
Follow IntellicoWorks for more insights!

